
-


-


-


WeChat


Контроллер резервирования сети
Когда слышишь ?контроллер резервирования сети?, многие инженеры первым делом представляют себе простое устройство для переключения между основным и резервным каналом. На деле же — это целый пласт логики, от которой зависит, будет ли система ?дышать? при сбое или захлебнется в собственных протоколах. В железнодорожной автоматике, особенно в системах мониторинга, типа тех, что делает ООО Сычуань Хунцзинжунь Технолоджи, эта тема выходит на первый план. Их системы, вроде онлайн-мониторинга заземляющих сетей или AI-платформы контроля безопасности, гонят огромные массивы данных в реальном времени. Потеря связи здесь — это не просто задержка отчёта, это потенциальный инцидент. И вот тут наш ?простой? контроллер превращается в ключевой узел.
Где тонко, там и рвётся: типичные грабли в проектировании
Основная ошибка, которую я часто видел в старых проектах — это отношение к резервированию как к задаче второго плана. Мол, ?поставим два свитча, настроим STP или какой-нибудь VRRP, и дело с концом?. В идеальном лабораторном стенде — да, работает. Но на реальной тяговой подстанции или вдоль железнодорожного полотна, где рядом силовые кабеля, работают мощные преобразователи, картина меняется. Помню случай с внедрением системы мониторинга дефектов подземных пустот. Контроллер резервирования был выбран стандартный, индустриальный. Но при тестовом отключении основного канала переключение занимало 8-12 секунд. Для системы, которая должна отслеживать динамические изменения в грунте, это вечность. Данные за этот интервал терялись безвозвратно, формируя ?слепое пятно? в истории событий. Оказалось, проблема была не в скорости линка, а в том, как контроллер опрашивал состояние каналов и валидировал сессию с верхнеуровневым SCADA-сервером. Там была сложная цепочка таймаутов, унаследованная от офисных решений.
Отсюда вывод, который сейчас кажется очевидным, но который приходится доказывать на каждом новом объекте: логика резервирования сети должна проектироваться под конкретный протокол передачи данных и его требования к целостности сессии. Для Modbus TCP, OPC UA, MQTT или проприетарного протокола от Хунцзинжунь Технолоджи — подходы будут разными. Нельзя взять универсальную коробку и надеяться на чудо.
Ещё один нюанс — это определение самого факта ?сбоя?. Потеря линка на физическом уровне (link down) — это просто. А если канал жив, но пакеты теряются или задерживаются из-за помех? Или если резервный канал изначально имеет меньшую пропускную способность (скажем, радиомост вместо оптоволокна)? ?Умный? контроллер должен уметь оценивать качество канала по нескольким метрикам: не только наличие несущей, но и процент потерь ICMP-пакетов, джиттер, доступность критического шлюза. И здесь уже начинается поле для кастомизации. В их системе позиционирования для безопасности на стройобъектах, например, важна минимальная латентность. Поэтому алгоритм должен быть жёстким: даже небольшой рост задержки на основном канале выше порога — инициировать плановое переключение, не дожидаясь полного обрыва.
Интеграция в экосистему: больше чем сетевая задача
Когда мы говорим про продукты для интеллектуализации железных дорог, вроде безлюдной эксплуатации подстанций или роботов для осмотра подвижного состава, контроллер резервирования перестаёт быть изолированным сетевым устройством. Он становится частью контура управления. Представьте: робот-инспектор в депо передаёт видео высокого разрешения и данные 3D-сканирования. Сеть должна обеспечить не просто связность, а гарантированную пропускную способность. При сбое основного канала, переключение должно быть таким, чтобы управляющий контроллер робота не потерял сессию, иначе весь процесс осмотра придётся начинать заново — это время и деньги.
В проекте с ООО Сычуань Хунцзинжунь Технолоджи по интеллектуальному энергоснабжению депо мы как раз столкнулись с необходимостью тесной интеграции их MES-системы с цифровым двойником и сетевой инфраструктурой. Контроллеру нужно было не просто переключить трафик, но и отправить событие в MES о смене активного пути, чтобы это отразилось в логике цифрового двойника. Иначе возникал разрыв между физическим состоянием сети и его виртуальной моделью. Пришлось реализовывать отдельный API-интерфейс на самом контроллере для оповещения верхнеуровневых систем. Это уже не boxed product, а практически кастомная разработка.
Кстати, о железе. Часто его недооценивают. В суровых условиях, будь то стройплощадка или полотно железной дороги, нужен широкий температурный диапазон, защита от вибрации и влаги. Стандартные коммерческие свитчи здесь могут не выжить. Мы пробовали в одном из первых пилотов по мониторингу контактной сети использовать перепрошитые промышленные маршрутизаторы. Но их внутренняя логика резервирования оказалась ?зашита? на слишком низком уровне и не давала нужной гибкости для работы с протоколами промышленной автоматики. В итоге перешли на специализированные устройства от другого вендора, которые позволили загружать собственные скрипты анализа состояния каналов.
Резервирование vs. Балансировка: тонкая грань
В современных системах, особенно где идёт поток данных с множества датчиков (как в системе предотвращения стихийных бедствий на ЖД-линиях), иногда встаёт вопрос: а нужно ли нам пассивное резервирование, когда один канал простаивает? Может, распределить нагрузку? Здесь кроется дилемма. Балансировка нагрузки увеличивает общую пропускную способность, но усложняет логику восстановления при отказе одного из каналов. Если канал падает, его нагрузку нужно экстренно перебросить на оставшийся, который может быть и так загружен. Возникает риск перегрузки и коллапса второго канала.
В нашем опыте для критических систем мониторинга, где данные носят событийный характер (например, обнаружение частичного разряда), мы всё же склонялись к классической схеме active-standby. Резервный канал абсолютно чист и готов мгновенно принять на себя весь поток. Да, это ?неэкономно? с точки использования ресурсов, но зато предсказуемо и надёжно. Для менее критичных фоновых задач — синхронизация журналов, передача архивных данных — можно использовать оба канала одновременно. Хороший контроллер резервирования сети должен поддерживать оба сценария, позволяя назначать политики для разных типов трафика. В документации к их роботам для ремонта моторвагонных поездов, кстати, чётко прописано: канал передачи управляющих команд — только по схеме с горячим резервом, а канал для передачи диагностических логов — может балансироваться.
Это приводит нас к важности тестирования. Нельзя настроить резервирование и забыть. Регулярные плановые переключения — обязательная процедура. Я видел печальные случаи, когда резервный канал, годами находившийся в режиме standby, в момент реальной аварии оказывался неработоспособным из-за банальной физической деградации кабеля или неправильно обновлённой таблицы маршрутизации где-то выше по потоку. Поэтому в идеале контроллер должен иметь встроенные средства для автоматического проведения таких тестов, например, в ночное окно, с генерацией отчёта для инженеров Хунцзинжунь Технолоджи или службы эксплуатации.
Будущее: программно-определяемые подходы
Сейчас всё больше говорят о SD-WAN для корпоративных сетей. В промышленном и транспортном секторе эта тенденция тоже набирает обороты, но со своей спецификой. Контроллер резервирования сети эволюционирует из отдельного аппаратного устройства в виртуальную функцию, работающую, возможно, на том же сервере, что и часть логики системы безопасности или цифровой двойник. Это даёт невиданную гибкость: политики резервирования можно менять на лету в зависимости от времени суток, загрузки пути, проводимых работ.
Например, во время планового ремонтного окна на участке, когда задействованы их роботы для инженерного строительства, можно динамически перераспределить приоритеты сетевых каналов, выделив больше ресурсов для управления роботами, а фоновый мониторинг временно перевести на более медленный канал. Или в случае получения сигнала от системы мониторинга стихийных бедствий о повышенной опасности — автоматически перевести все каналы связи с критическими датчиками в режим максимальной отказоустойчивости, даже в ущерб другим данным.
Внедрение таких систем — это уже следующий уровень. Это требует тесной интеграции на уровне программных интерфейсов между сетевым оборудованием, контроллером резервирования и прикладным ПО, таким как интеллектуальная платформа от ООО Сычуань Хунцзинжунь Технолоджи. Пока это скорее точечные пилоты, но направление очевидно. Жёсткая привязка к ?железке? уходит в прошлое, на первый план выходит интеллектуальная логика управления сетевыми потоками как часть общей системы управления объектом.
Заключительные штрихи: надёжность как процесс
Так к чему же мы пришли? Контроллер резервирования сети — это не ?поставил и забыл?. Это живой, постоянно развивающийся компонент. Его выбор, настройка и эксплуатация — это процесс, требующий глубокого понимания не только сетевых технологий, но и специфики прикладных задач, которые он обслуживает. Будь то обеспечение бесперебойной связи для AI-платформы контроля безопасности персонала или для системы питания обслуживания контактной сети.
Ошибки на этом этапе дорого обходятся. Но и слепое следование ?стандартным? решениям без оглядки на реальные условия работы — тупиковый путь. Нужно смотреть на продукт комплексно: от физического уровня и устойчивости к помехам до тонкостей протоколов прикладного уровня и интеграции с системами управления. Именно такой подход позволяет строить по-настоящему отказоустойчивые инфраструктуры для ответственных объектов, будь то железная дорога, умное депо или тяговая подстанция. И в этом контексте, решения, предлагаемые компаниями вроде Хунцзинжунь Технолоджи, которые сами глубоко погружены в предметную область, имеют неоспоримое преимущество — они понимают, для чего и в каких условиях должна работать эта сетевая отказоустойчивость.
Соответствующая продукция
Соответствующая продукция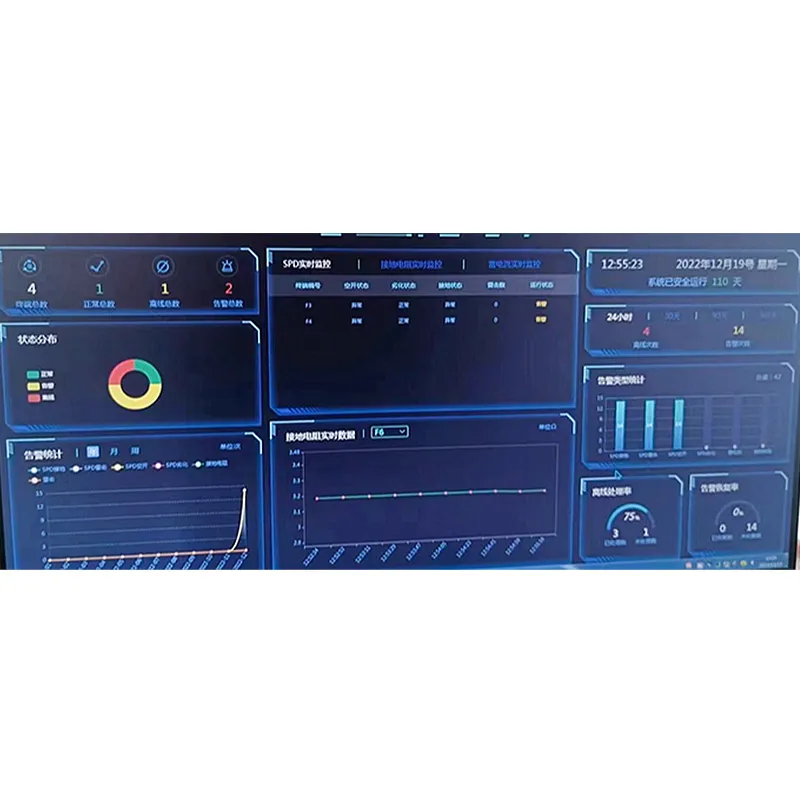


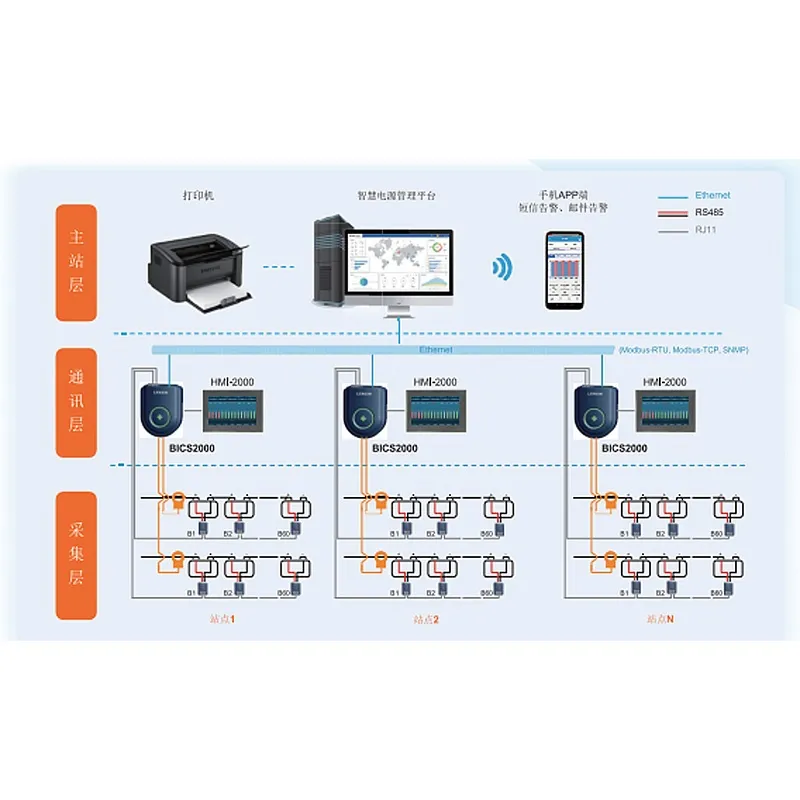


Самые продаваемые продукты
Самые продаваемые продукты-
 Параллельная интегрированная система электропитания
Параллельная интегрированная система электропитания -
 Система гарантированного питания постоянного тока
Система гарантированного питания постоянного тока -
 Робот для инспекции подстанций (внешнего применения)
Робот для инспекции подстанций (внешнего применения) -
 Промышленный шлюз
Промышленный шлюз -
 Беспилотный летательный аппарат для инспекции контактной сети
Беспилотный летательный аппарат для инспекции контактной сети -
 Устройство прогнозного предупреждения об отказе аккумуляторных батарей
Устройство прогнозного предупреждения об отказе аккумуляторных батарей -
 Прецизионный трансформатор тока
Прецизионный трансформатор тока -
 Система онлайн-мониторинга газа SF6
Система онлайн-мониторинга газа SF6 -
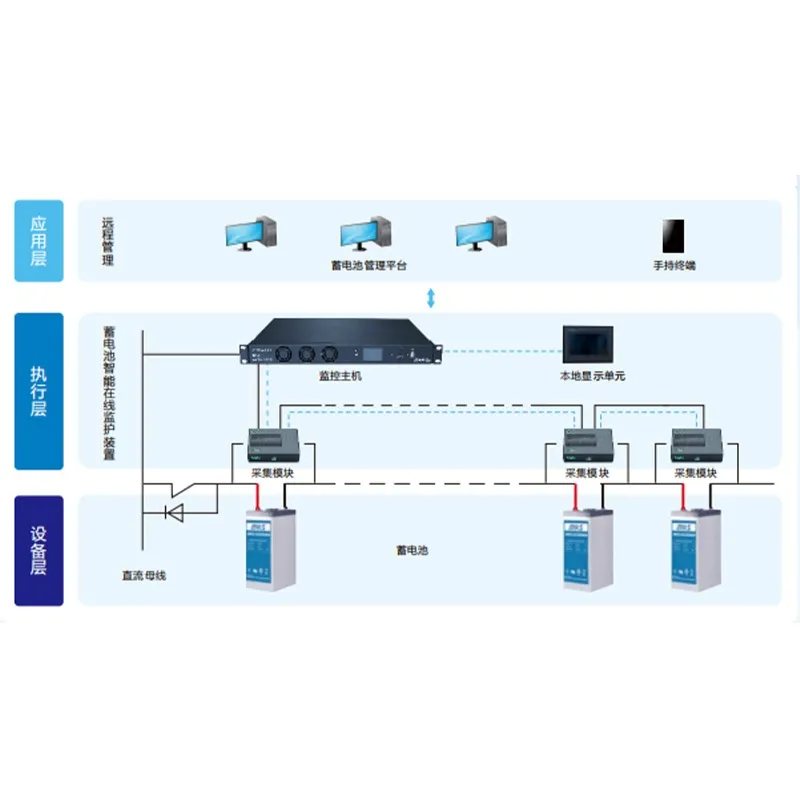 Устройство онлайн-контроля и защиты аккумуляторных батарей
Устройство онлайн-контроля и защиты аккумуляторных батарей -
 Интегрированная система электропитания переменного/постоянного тока
Интегрированная система электропитания переменного/постоянного тока -
 Изолятор
Изолятор -
 Портативный детектор частичных разрядов
Портативный детектор частичных разрядов
Связанный поиск
Связанный поиск- rtu 325
- изоляторы линейные штыревые фарфоровые шф 10 мо
- изолятор керамический опорный
- Модульный параллельный источник питания для систем связи
- промышленный интеллектуальный шлюз
- Система бесперебойного питания постоянного тока
- изолятор ио 10 3.75
- изолятор тн вэд
- измеритель сопротивления заземления ekf
- успд rtu 325